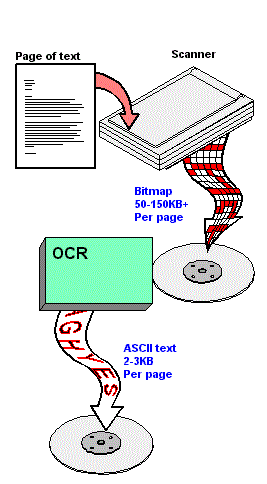
Optical character recognition, usually abbreviated to OCR, is computer software designed to translate images of handwritten or typewritten text (usually captured by a scanner) into machine-editable text or to translate pictures of characters into a standard encoding scheme representing them (e.g. ASCII or Unicode).
OCR began as a field of research in pattern recognition, artificial intelligence, and machine vision. Though academic research in the field continues, the focus on OCR has shifted to implementation of proven techniques.
Optical character recognition (using optical techniques such as mirrors and lenses) and digital character recognition (using scanners and computer algorithms) were originally considered separate fields. Because very few applications survive that use true optical techniques, the optical character recognition term has now been broadened to cover digital character recognition as well.
Early systems required “training” (essentially, the provision of known samples of each character) to read a specific font. Currently, though, “intelligent” systems that can recognize most fonts with a high degree of accuracy are now common.
Some systems are even capable of reproducing formatted output that closely approximates the original scanned page including images, columns and other non-textual components.
The accurate recognition of Latin-script, typewritten text is now considered largely a solved problem.
Recognition of hand printing, cursive handwriting, and even the printed typewritten versions of some other scripts (especially those with a very large number of characters), are still the subject of active research.